先來看一下 long long 跟 float ,long long的size是8個byte,float的size是4個byte
long long * float,compiler會將結果存到float的temp變數裡,此時誤差就可能會出現了,但是這個誤差是「有條件」地出現,並不是任何long long的數字乘上float都會產生誤差的
以一個簡單的程式來驗證是否會產生誤差
bool check_longlong(long long v1)
{
float f = 1.0f;
long long v2 = long long( v1 * f );
printf("ori value=%lld, new value=%lld, ori==new=%d", v1, v2, v1==v2);
return v1==v2;
}
int _tmain(int argc, _TCHAR* argv[])
{
check_longlong(0xF0000000000);//true - OK
check_longlong(0x0FFFFFFFFFF);//false - Error!
check_longlong(0x0FFFFFF);//true - OK
check_longlong(0x1FFFFFF);//false - Error!
return 0;
}
Float
研究一下float的binary data的組成.... |
| Reference from Wiki |
 |
| Reference from Wiki |
exponent :8 bit - 表示fraction的2次方值
fraction : 23 bit - 表示正規化後的數值(實際上可表示24bit,因為小數點前永遠為1)
由這示意圖可以發現,float的精準度就靠fraction的23bit(可表達24bit的數字),因此,理論上只要與float相乘的數字binary值,第一個1跟最後一個1相差超過24的話,即會overflow產生誤差,不管是乘以long long(64bit) or int(32bit),因為float最多就只能表達24bit的數字,你硬要塞25bit以上的數字,肯定會被crop或round掉的。所以,並不是數字太大就會有問題,而且前後的1相差超過float能表示的範圍才會有問題。
範例:
- 0x0FFFFFF = (0000111111111111111111111111)2 - OK
- 0x1FFFFFF = (0001111111111111111111111111)2 - Error
- 0x2FFFFFF = (0010111111111111111111111111)2 - OK
- 0x1000001 = (0001000000000000000000000001)2 - Error
- 0xFFFFFF0 = (1111111111111111111111110000)2 - OK
注意上面紅色的1,代表第一個1與最後一個1
Double
同樣的道理,來看看double需要多大的值才會產生誤差呢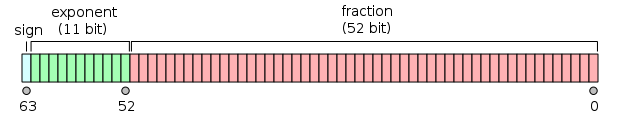 |
| Reference from Wiki |
- 0x1FFFFFFFFFFFFF = 9,007,199,254,740,991L - OK
- 0x2FFFFFFFFFFFFF = 13,510,798,882,111,487L - Error
- 0x10000000000001 = 4,503,599,627,370,497L - OK
- 0x20000000000001 = 9,007,199,254,740,993L - Error
著實是非常大的數字.... =_=""
Windows 32bit 沒誤差!?(安全下莊)
同樣的一套邏輯,在Windows 32bit, 64bit的AP卻有不一樣的結果,64bit會產生誤差,32bit卻不會產生誤差,why!? 用VisualStudio 2005與2008試了以後是一樣的結果,看了一下assembly code,x86與x64的指令是不一樣的,這應該就是產生不一樣結果的徵結點吧。
用SIMD的cvtsi2ss先將longlong轉成float,相乘後,再用cvttss2si轉回longlong的值,這標準的longlong與float轉換,就會產生誤差!
x64 assembly code
float f = 1.0f; 0000000140001043 movss xmm0,dword ptr [__real@3f800000 (1400057C0h)] 000000014000104B movss dword ptr [f],xmm0 long long v2 = long long(v1 * f); 0000000140001051 cvtsi2ss xmm0,qword ptr [v1] 0000000140001058 mulss xmm0,dword ptr [f] 000000014000105E cvttss2si rax,xmm0 0000000140001063 mov qword ptr [v2],rax
再看一下VC compile出來的x86的assembly code:
x86用fild和fmul做floating point的運算,最後再以ftol2將float轉成long long,看了一下說明,fild會將integer(16, 32, 64bit)轉成80bit extension precision的float值,擁有80bit的precision乘完後的結果,直接轉成long long,當然不會有誤差囉!
x86 assembly code
float f = 1.0f; 0041140E fld1 00411410 fstp dword ptr [f] long long v2 = long long(v1 * f); 00411413 fild qword ptr [v1] 00411416 fmul dword ptr [f] 00411419 call @ILT+435(__ftol2) (4111B8h) 0041141E mov dword ptr [v2],eax 00411421 mov dword ptr [ebp-14h],edx
沒有留言:
張貼留言